Código 2
Módulo 1- Unidad 1.1
dgonzalez
1. Introducción
Al tener una base de datos se requiere resumirlos en una tabla o en indicadores que faciliten su análisis, dependiendo el tipo de variable ( cualitativas o cuantitativas) la tabla puede tener diferentes columnas.
En el caso de los indicadores las variables cualitativas se les resumen en el nivel con mayor frecuencias a la que se le llama MODA
Las variables cuantitativas tiene un gran número de indicadores que se dividien en tres categorias:
- Indicadores de tendencia central
- Indicadores de dispersión
- Indicadores de forma
A continuación se indica como realizar el proceso utilizando RStudio, bajo el supuesto que se cuenta con una base de datos que se ha importado en RStudio.
2. Tablas de frecuencia
Resumirlos datos en tablas facilita su análisis y también su representación gráfica. Varios gráficos están basados en tablas de frecuencia como veremos en la unidad 1.3
Antes de empezar vamos a cargar la base construida en el código anterior y las dos bases de Dataset de R
- Base de datos Colombia
Colombia=readRDS(file = "data/Colombia.RDS")- Base de datos iris
iris=data(iris)- Base de datos ventas
library(readr)
ventas <- read_csv("data/ventas.csv")Tablas variables cualitativas
Iniciaremos con la construcción de tablas para variables cualitativas en escala nominal. Recordemos que las variables medidas en esta escala no presentan orden especial y en algunos casos son ordenadas de mayor a menor frecuencia
Utilizaremos en este caso la función table()
table(ventas$Metodo_Pago)
American Express Discover MasterCard Star Card
4 8 28 140
Visa
20 El resultado corresponde a un conteo de cada uno de los valores de la variable. En caso de que se requiera calcular la proporción que corresponde cada caso utilizamos la función : prop.table() y se la aplicamos a la tabla anterior
t1=table(ventas$Metodo_Pago)
prop.table(t1)
American Express Discover MasterCard Star Card
0.02 0.04 0.14 0.70
Visa
0.10 Si utilizamos la función freq del paquete summarytools, la salida es una tabla más elaborada
summarytools::freq(ventas$Metodo_Pago, cumul = F)Frequencies
Freq % Valid % Total
---------------------- ------ --------- ---------
American Express 4 2.00 2.00
Discover 8 4.00 4.00
MasterCard 28 14.00 14.00
Star Card 140 70.00 70.00
Visa 20 10.00 10.00
<NA> 0 0.00
Total 200 100.00 100.00Tablas variables cuantitativas
Para el caso de las variables cuantitativas que presentan muchos valores difentes construir una tabla como las anteriores no tiene sentido, pues salen muchas categorias probablemente con frecuencia uno.
En este caso es necesario construir rangos que den sentido y que permitan resumir la información para una facil interpretación.
El ejemplo a continuación da cuenta de ello. Supongamos que queremos analizar la variable edad y para ello debemos establecer los limites y cuantos intervalo vamos aconstruir. En este caso tenemos tres alternativas posible_
- Tomar los intervalos construidos en un estudio anterior con cual queremos comparar los nuestros
- Tomar intervalos de acuerdo a estudios anteriores o teorias sobre el tema
- Tomar intervalos de igual longitud. En este caso existen diferentes alternativas para establecer el numero de intervalos a construir. Uno de ellos indica como respuesta a este interrogante la formula construida por Sturgues (se puede conocer mediante la función nclass.Sturges(variable) ) que es utilizada por otras funcione en R
En el caso de la variable Edad procederemos asi:
Consultados los ciclos de la vida tenemos: + Primera Infancia (0-5 años) + Infancia (6 - 11 años) + Adolescencia (12 - 17 años) + Juventud (18 - 26 años) + Adultez (27- 59 años) + Persona Mayor (60 años o mas) envejecimiento y vejez
Colombia$edadR[Colombia$edad<=5]="1. (0 a 5 años]"
Colombia$edadR[Colombia$edad>5 & Colombia$edad<=11]="2. (5 a 11 años]"
Colombia$edadR[Colombia$edad>11 & Colombia$edad<=17]="3. (11 a 17 años]"
Colombia$edadR[Colombia$edad>17 & Colombia$edad<=26]="4. (17 a 26 años]"
Colombia$edadR[Colombia$edad>26 & Colombia$edad<=59]="5. (26 a 59 años]"
Colombia$edadR[Colombia$edad>59]="6. (Más de 59 años]"
summarytools::freq(Colombia$edadR)Frequencies
Freq % Valid % Valid Cum. % Total % Total Cum.
------------------------- --------- --------- -------------- --------- --------------
1. (0 a 5 años] 85231 1.72 1.72 1.72 1.72
2. (5 a 11 años] 133173 2.69 4.41 2.69 4.41
3. (11 a 17 años] 210175 4.24 8.65 4.24 8.65
4. (17 a 26 años] 812872 16.40 25.04 16.40 25.04
5. (26 a 59 años] 2994915 60.41 85.46 60.41 85.46
6. (Más de 59 años] 720911 14.54 100.00 14.54 100.00
<NA> 0 0.00 100.00
Total 4957277 100.00 100.00 100.00 100.00Esta tabla nos permite identificar los rangos de mayor frecuencia
Tambien podemo realizar una tabla sin tener que realizar la recodificación. Esto se logra con la función hist()
h=hist(Colombia$edad)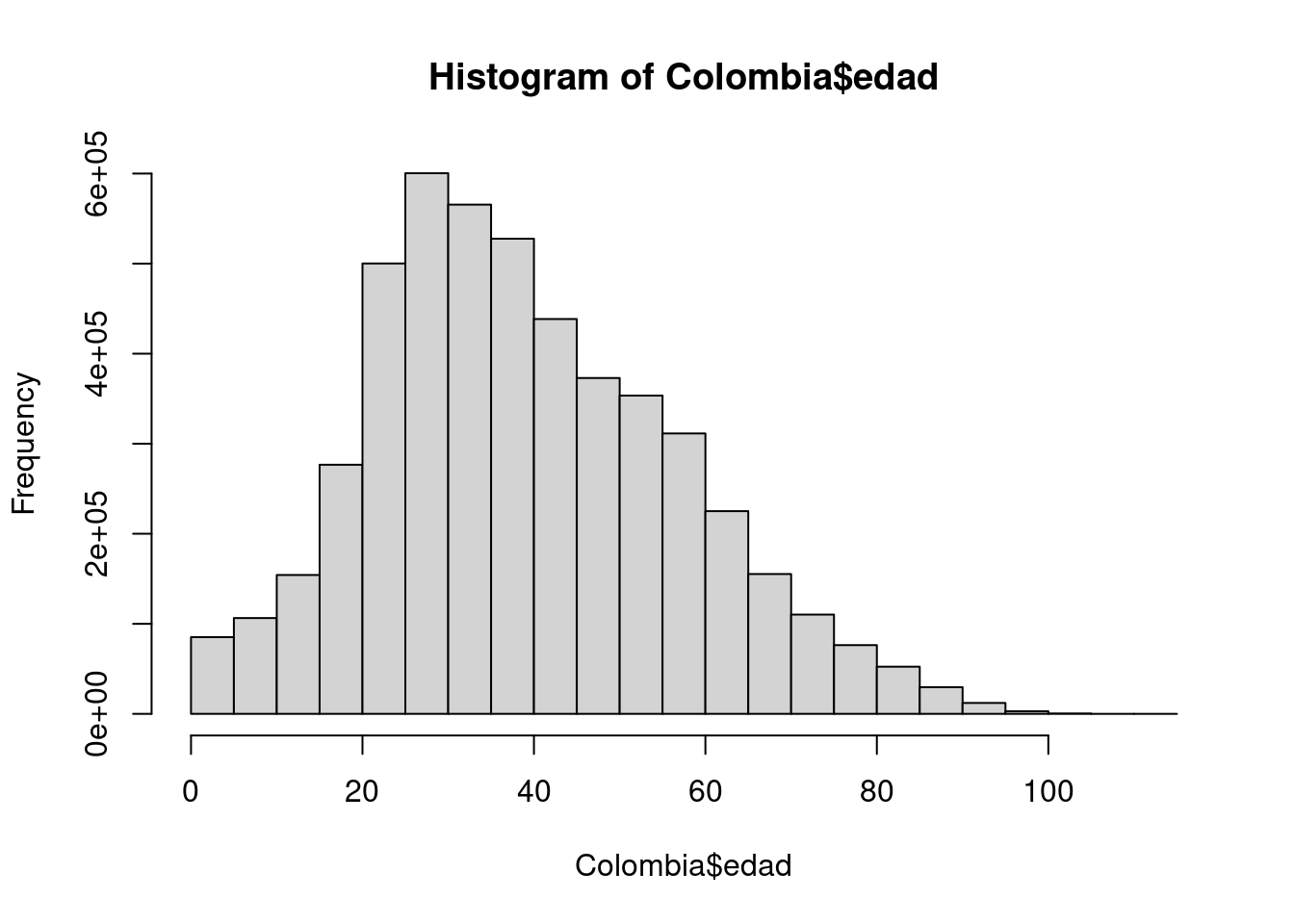
h$breaks # puntos de corte [1] 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90
[20] 95 100 105 110 115h$counts # frecuencias absolutas en cada intervalo [1] 85231 106425 154254 276652 500172 600444 565521 527664 438458 373003
[11] 353469 311391 225137 155264 110274 76346 52419 29604 12119 2947
[21] 425 49 9h$density # densidad en cada intervalo [1] 3.438622e-03 4.293688e-03 6.223336e-03 1.116145e-02 2.017930e-02
[6] 2.422475e-02 2.281579e-02 2.128846e-02 1.768947e-02 1.504871e-02
[11] 1.426061e-02 1.256299e-02 9.083091e-03 6.264084e-03 4.448975e-03
[16] 3.080159e-03 2.114830e-03 1.194365e-03 4.889378e-04 1.188959e-04
[21] 1.714651e-05 1.976892e-06 3.631026e-07Seria de interés tambien construir una tabla con las edades de las personas fallecidas por covid en Colombia, para lo cual debemos primero seleccionar la base de datos de las fallecidas y luego en ello construir la tabla
En este caso vamos a seleccionar los rangos de edad y luego construimos la tabla
Fallecidos=subset(Colombia, estado=="fallecido")
breaks=seq(0,110, by=10)
Edad.fallecidos=cut(Fallecidos$edad, breaks)
summarytools::freq(Edad.fallecidos)Frequencies
Freq % Valid % Valid Cum. % Total % Total Cum.
--------------- -------- --------- -------------- --------- --------------
(0,10] 144 0.11 0.11 0.11 0.11
(10,20] 231 0.18 0.30 0.18 0.30
(20,30] 1683 1.33 1.63 1.33 1.63
(30,40] 4802 3.80 5.43 3.80 5.43
(40,50] 10411 8.24 13.67 8.24 13.67
(50,60] 20589 16.30 29.98 16.30 29.98
(60,70] 30534 24.18 54.15 24.18 54.15
(70,80] 30803 24.39 78.54 24.39 78.54
(80,90] 21742 17.21 95.76 17.21 95.76
(90,100] 5206 4.12 99.88 4.12 99.88
(100,110] 154 0.12 100.00 0.12 100.00
<NA> 0 0.00 100.00
Total 126299 100.00 100.00 100.00 100.00O tambien
h=hist(Colombia$edad, breaks = c(0,4.9, 11.9,17.9,26.9, 59.9,115))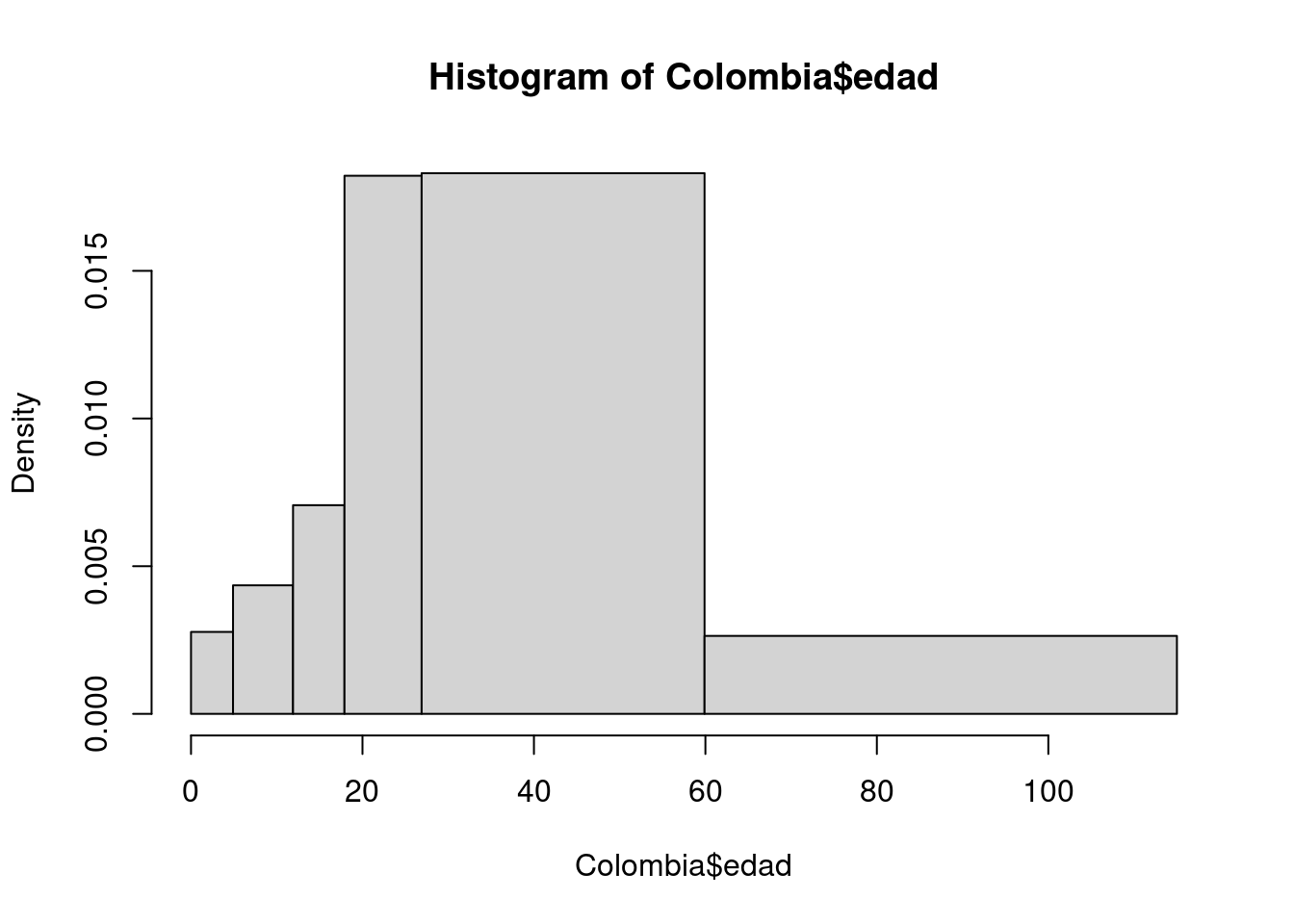
# Con los valores contenidos en el objeto h construimos la tabla
LI=h$breaks[1:6]
LS=h$breaks[2:7]
FreAbs=h$counts
FreRel=round(h$counts/sum(h$counts),4)
FreAbAc=cumsum(FreAbs)
FreRAc=cumsum(FreRel)
data.frame(LI,LS,FreAbs,FreRel, FreAbAc, FreRAc) LI LS FreAbs FreRel FreAbAc FreRAc
1 0.0 4.9 67381 0.0136 67381 0.0136
2 4.9 11.9 151023 0.0305 218404 0.0441
3 11.9 17.9 210175 0.0424 428579 0.0865
4 17.9 26.9 812872 0.1640 1241451 0.2505
5 26.9 59.9 2994915 0.6041 4236366 0.8546
6 59.9 115.0 720911 0.1454 4957277 1.0000Tablas de doble entrada
table(Colombia$ubicacion, Colombia$estado)
fallecido grave leve moderado
casa 0 0 4803358 0
fallecido 126299 0 0 0
hospital 0 0 0 7950
hospital uci 0 993 0 0tabla1=table(Colombia$ubicacion, Colombia$estado)
prop.table(tabla1)
fallecido grave leve moderado
casa 0.0000000000 0.0000000000 0.9726153161 0.0000000000
fallecido 0.0255738468 0.0000000000 0.0000000000 0.0000000000
hospital 0.0000000000 0.0000000000 0.0000000000 0.0016097680
hospital uci 0.0000000000 0.0002010691 0.0000000000 0.00000000003. Indicadores descriptivos
Un indicador es un numero que resumen o representa un grupo de valores. El poder resumir una gran cantidad de valores en unos pocos, facilita el realizar un análisis de ellos
En el caso de las variables cualitativas en escala nominal, se pueden representar por el valor mas frecuente. A este valor se le conoce como Moda y lo podemos ver claramente en una tabla de frecuencias
En el caso de las variables cuantitativas debemos de construirlos
summary(Colombia$edad) Min. 1st Qu. Median Mean 3rd Qu. Max.
1.0 26.0 37.0 39.5 52.0 114.0 psych::describe(Colombia$edad) vars n mean sd median trimmed mad min max range skew kurtosis
X1 1 4957277 39.5 17.94 37 38.72 17.79 1 114 113 0.41 -0.17
se
X1 0.01psych::describe.by(Colombia$edad, group = Colombia$ubicacion)
Descriptive statistics by group
group: casa
vars n mean sd median trimmed mad min max range skew kurtosis
X1 1 4803358 38.64 17.3 37 37.96 17.79 1 114 113 0.39 -0.16
se
X1 0.01
------------------------------------------------------------
group: fallecido
vars n mean sd median trimmed mad min max range skew kurtosis
X1 1 126299 67.56 15.28 69 68.42 14.83 1 110 109 -0.53 0.15
se
X1 0.04
------------------------------------------------------------
group: hospital
vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 7950 47.8 22.08 49 48.62 22.24 1 100 99 -0.26 -0.52 0.25
------------------------------------------------------------
group: hospital uci
vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 993 51.94 20.08 54 53.25 20.76 1 98 97 -0.54 -0.18 0.64summarytools::descr(Colombia$edad)Descriptive Statistics
value
N: 4957277
value
----------------- ------------
Mean 39.50
Std.Dev 17.94
Min 1.00
Q1 26.00
Median 37.00
Q3 52.00
Max 114.00
MAD 17.79
IQR 26.00
CV 0.45
Skewness 0.41
SE.Skewness 0.00
Kurtosis -0.17
N.Valid 4957277.00
Pct.Valid 100.00
YA ESTAMOS LISTOS PARA INTERPRETAR LA INFORMACION
4. Documentos pdf
A través de RStudio se pueden construir documentos en formatos PDF, DOC, HTML entre otros. En esta ocasión se describe como realizar un informe utilizando para ello un archivo Rmd en RStudio.
Inicialmente en RStudio abrimos un nuevo archivo en formato Rmd
File/New File/ R Markdown…
Al hacerlo se despliega la siguiente ventana
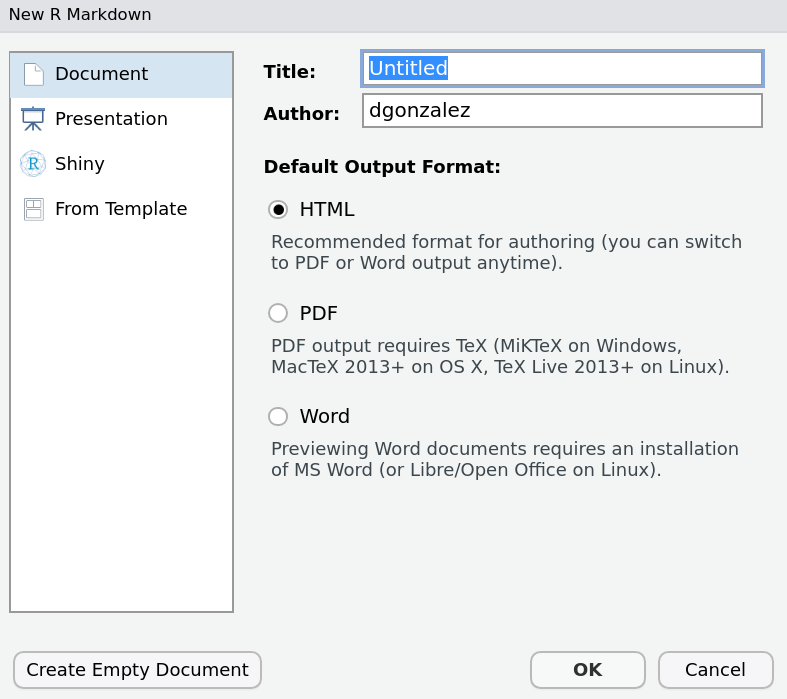
En este caso seleccionamos PDF para abrir una plantilla que nos ofrece el programa para orientar nuestros primeros pasos
---
title: "Untitled"
author: "dgonzalez"
date: "3/8/2021"
output: pdf_document
---El primer bloque contiene información sobre el titulo del documento, el autor, la fecha y el formato de salida
Podemos tambien abregar un subtitulo: subtitle: “Subtitulo”
Despues de este bloque encontramos el cuerpo del documento que puede contener texto escrito de manera normal, código html, código Markdown y LaTeX
Algunas de las principales instrucciones para empezar son
Titulos
# Título 1
## Título 2
### Título 3
#### Título 4
##### Título 5
##### Títuñlo 6Listas
+ Punto 1
+ Punto 2
+ Punto 3
+ Punto 3.1
+ Punto 3.2Tambien se pueden hacer numerada
1. Punto 1
2. Punto 2
3. Punto 3- Punto 1
- Punto 2
- Punto 3
Permite tambien escribir ecuaciones en codigo LaTeX, como por ejemplo
$$\dfrac{1}{n}\sum_{i=1}^{n} x_{i} = \bar{x}$$\[\dfrac{1}{n}\sum_{i=1}^{n} x_{i} = \bar{x}\]
Una de sus principales ventajas es el de permitir correr código R y de otros lenguajes como Phyton, SQL, entre otros
Para ello utilizamos el botón +c ubicado en la barra superior de la ventana Source
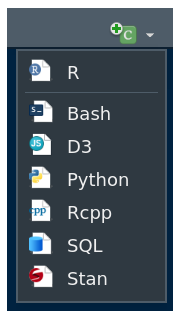
Dentro de este bloque podemos correr codigo R y asi ubicar dentro del documento tablas, indicadores o gráficos

En la siguiente página pueden encotrar resumen de varios paquetes de R dentro de los cuales está RMardown